
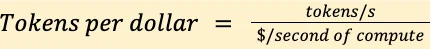

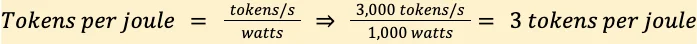
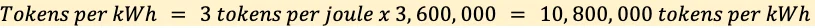
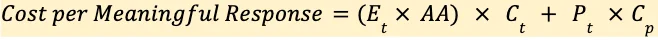

Setiap kata yang muncul di layar ChatGPT atau Perplexity melibatkan proses kompleks bernama inference (inferensi). Ini mekanisme utama sistem AI menghasilkan pendapatan—dan Eduardo Alvarez dari O'Reilly menganalisisnya dengan prinsip ekonomi bisnis dasar.1 Tujuannya sederhana. Memastikan sistem AI yang kita operasikan mampu memberikan hasil positif berkelanjutan.
Token sebagai Unit Ekonomi AI
Token adalah representasi vektor dari teks. Model bahasa memproses urutan token input, lalu menghasilkan token untuk merumuskan respons.1 Bayangkan pabrik perakitan mobil—efektivitasnya diukur dari berapa banyak kendaraan diproduksi per jam. Begitu pula "pabrik token" AI.
Ketika pengguna bertanya, "Apa obat tradisional untuk flu?" frasa itu dikonversi menjadi representasi vektor yang mengalir melalui model terlatih. Jutaan komputasi matriks paralel mengekstrak makna dan konteks untuk menentukan kombinasi token output paling efektif.1
Price-Performance vs Total Cost of Ownership
Untuk sistem AI, khususnya large language models (LLM), efektivitas diukur lewat analisis price-performance (harga-kinerja). Ini berbeda dari Total Cost of Ownership (TCO) karena bisa dioptimalkan secara operasional dan bervariasi antar beban kerja.1 TCO terutama terdiri dari biaya komputasi—biasanya biaya sewa atau kepemilikan kluster GPU per jam. Namun analisis TCO sering mengabaikan biaya teknik signifikan untuk memelihara perjanjian tingkat layanan (SLA), termasuk debugging dan patching sistem.
| Metrik 📊 | Definisi | Faktor Kunci |
|---|---|---|
| Tokens per Dollar | Jumlah token yang dapat diproses per unit mata uang | Ukuran model, arsitektur, biaya komputasi |
| Tokens per Watt | Efisiensi energi dalam menghasilkan token | Konsumsi daya GPU, desain server, pendinginan |
| Cost per Response | Biaya per respons bermakna (termasuk reruns) | Token rata-rata, tingkat keberhasilan, preprocessing |
| Throughput | Token yang dihasilkan per detik | Framework inference, optimasi kernel |
| Power Draw | Konsumsi daya aktual saat operasi | TDP vs pengukuran real, fase context/decode |
| TCO | Total biaya kepemilikan sistem | GPU, infrastruktur, maintenance engineering |
| SLA Costs | Biaya memenuhi perjanjian layanan | Debugging, patching, augmentasi sistem |
Efisiensi Biaya: Tokens per Dollar
Tokens per dollar (tok/$) mengintegrasikan throughput model dengan biaya komputasi. Rumusnya:1
tok/$ = (tokens/s) / ($/second compute)
Di mana tokens/s adalah throughput terukur, dan $/second compute adalah biaya efektif menjalankan model per detik (misal harga GPU-hour dibagi 3.600). Beberapa faktor penentu:
- Ukuran model: Model lebih besar memerlukan lebih banyak komputasi per token, berdampak langsung pada efisiensi biaya meskipun performa pemodelan bahasa umumnya lebih baik.1
- Arsitektur model: Arsitektur dense (LLM tradisional) komputasi per tokennya tumbuh linier atau superlinier dengan kedalaman atau ukuran layer. Mixture of experts (LLM sparse lebih baru) memisahkan komputasi per token dari jumlah parameter dengan hanya mengaktifkan bagian model tertentu—lebih efisien.1
- Software stack: Peluang optimasi signifikan ada di sini—memilih framework inference optimal seperti vLLM, SGLang, dan TensorRT-LLM dapat meningkatkan efisiensi dramatis.1
- Kebutuhan use case: Aplikasi layanan pelanggan biasanya memproses kurang dari beberapa ratus token per permintaan lengkap. Riset mendalam atau tugas code-generation kompleks sering memproses puluhan ribu token.1
Pemisahan Fase Context dan Decode
Praktis untuk memisahkan sumber daya komputasi yang dikonsumsi untuk fase pemrosesan input (context) dan fase generasi output (decode). Setiap fase punya persyaratan waktu, memori, dan perangkat keras berbeda yang memengaruhi throughput dan efisiensi keseluruhan.1 Komponen pemrosesan context dari inference biasanya singkat tapi terikat komputasi karena perhitungan paralel tinggi yang mengisi core. Generasi urutan output lebih terikat memori tetapi berlangsung lebih lama.
Efisiensi Energi: Tokens per Watt
Daya grid telah muncul sebagai kendala operasional utama untuk pusat data di seluruh dunia. Banyak fasilitas kini mengandalkan generator bertenaga gas untuk keandalan jangka pendek, sementara proyek nuklir multigigawatt sedang berlangsung untuk memenuhi permintaan jangka panjang.1 Kekurangan daya membuat analisis efisiensi energi menjadi komponen kritis ekonomi AI.
Dalam lingkungan ini, tokens per watt-second (TPW) menjadi metrik penting yang menangkap bagaimana infrastruktur dan perangkat lunak mengubah energi menjadi output inference berguna.1 Rumusnya:
TPW = tokens/s / watts
Contoh bot layanan pelanggan e-commerce dengan perilaku operasional:1
- Token dihasilkan per detik: 3.000 tokens/s
- Rata-rata konsumsi daya perangkat keras (GPU plus server): 1.000 watt
- Total waktu operasional untuk 10.000 permintaan pelanggan: 1 jam (3.600 detik)
TPW = 3.000 / 1.000 = 3 tokens/watt-second
Atau dalam kilowatt-hour (kWh): 3 × 3,6 juta = 10,8 juta tokens/kWh1
Dengan biaya rata-rata nasional $0,17/kWh, biaya energi per token adalah $0,000000017. Bahkan peningkatan efisiensi sederhana melalui optimasi algoritma atau kompresi model dapat menghasilkan penghematan biaya operasional bermakna.1 Permintaan kuat dari sektor AI telah mendorong harga chip memori melonjak, menurut analis.2
Biaya per Respons Bermakna
Meskipun biaya per token berguna, biaya per unit nilai bermakna—biaya per ringkasan, terjemahan, kueri riset, atau panggilan API—mungkin lebih penting untuk keputusan bisnis.1
Bergantung pada use case, biaya respons bermakna dapat mencakup "rerun" yang didorong kualitas atau error dan komponen pra/pascapemrosesan seperti embedding untuk retrieval-augmented generation (RAG):1
Cost per Response = (E_t × AA × C_t) + (P_t × C_p)
Di mana E_t adalah rata-rata token yang dihasilkan per respons, AA adalah rata-rata percobaan per respons bermakna, C_t adalah biaya per token, P_t adalah rata-rata token pra/pascapemrosesan, dan C_p adalah biaya per token pra/pascapemrosesan.1
Contoh perhitungan untuk bot layanan pelanggan e-commerce: Respons rata-rata 100 token reasoning + 50 token output standar (150 total), tingkat keberhasilan 1,2 percobaan rata-rata, biaya per token $0,00015, pemrosesan guardrail 150 token di $0,000002 per token.1
Cost = (150 × 1,2 × 0,00015) + (150 × 0,000002) = $0,027 + $0,0003 = $0,0273
Perhitungan ini menentukan harga berkelanjutan untuk mengoptimalkan profitabilitas layanan. Analisis serupa dapat dilakukan untuk menentukan efisiensi daya dengan mengganti metrik biaya per token dengan ukuran joule per token.1
Tren Industri dan Infrastruktur
OpenAI dan Foxconn bermitra untuk melokalisasi manufaktur infrastruktur AI di Amerika, merespons biaya yang terus meningkat.3 Meta menghadapi gelombang biaya AI yang akan datang, namun para analis menyarankan investor bertahan hingga 2026 karena investasi jangka panjang.4
Model AI China berbiaya rendah terus maju bahkan di AS, meningkatkan risiko "gelembung AI" yang berpusat pada investasi tinggi model AS.5 Perusahaan global akan menghabiskan setidaknya $5 miliar pada 2027 untuk merombak sistem kepatuhan karena regulasi AI yang saling bertentangan di berbagai negara.6
Kesimpulan
Metrik tokens per dollar dan tokens per watt menyediakan fondasi untuk ekonomi AI. Namun sistem produksi beroperasi dalam lanskap optimasi jauh lebih kompleks.1 Struktur biaya sebenarnya dari sistem AI mencakup beberapa lapisan yang saling terhubung—dari pemrosesan token individual melalui arsitektur komputasi hingga desain pusat data dan strategi deployment.
Setiap pilihan arsitektur berdampak cascading melalui seluruh stack ekonomi. Memahami hubungan berlapis ini sangat penting untuk membangun sistem AI yang tetap layak secara ekonomis saat mereka berkembang dari prototipe ke produksi.1 AI dapat memangkas biaya pengembangan SaaS tanpa mengorbankan kualitas jika diselaraskan dengan hambatan bisnis.7
Daftar Pustaka
- Alvarez, Eduardo. "Balancing Cost, Power, and AI Performance." AI and ML Radar, O'Reilly, 4 November 2025, https://www.oreilly.com/radar/balancing-cost-power-and-ai-performance/
- South China Morning Post. "Memory chip prices surge amid strong demand from the AI sector: analysts." 22 November 2025, https://www.scmp.com/tech/tech-trends/article/3333746/memory-chip-prices-surge-amid-strong-demand-ai-sector-analysts
- TechWire Asia. "Why OpenAI's deal with Foxconn matters: Localising AI infrastructure as costs mount." 21 November 2025, https://techwireasia.com/2025/11/openai-foxconn-partnership-1-4t-ai-infrastructure-bet/
- 24/7 Wall St. "A Wave of AI Costs Will Hit Meta. Why It's Worth Holding On Through 2026." 19 November 2025, https://247wallst.com/investing/2025/11/19/a-wave-of-ai-costs-will-hit-meta-why-its-worth-holding-on-through-2026/
- Chatham House. "Low-cost Chinese AI models forge ahead, even in the US, raising the risks of a US AI bubble." 20 November 2025, https://www.chathamhouse.org/2025/11/low-cost-chinese-ai-models-forge-ahead-even-us-raising-risks-us-ai-bubble
- The Hindu Business Line. "Compliance costs due to AI regulations to go up to $5 billion by 2027." 19 November 2025, https://www.thehindubusinessline.com/info-tech/compliance-costs-due-to-ai-regulations-to-go-up-to-5-billion-by-2027/article70299122.ece
- Forbes. "How AI Can Cut SaaS Development Costs Without Sacrificing Quality." 19 November 2025, https://www.forbes.com/councils/forbestechcouncil/2025/11/19/how-ai-can-cut-saas-development-costs-without-sacrificing-quality/