
Dalam era dimana artificial intelligence (kecerdasan buatan) semakin mendominasi berbagai aspek kehidupan, sebuah tantangan besar muncul: bagaimana kita bisa mempercayai sistem yg menilai kualitas AI itu sendiri? 1 Penelitian terbaru dari DataRobot mengungkap bahwa sistem LLM-as-a-Judge dapat "ditipu" oleh jawaban yang terdengar percaya diri namun salah, memberikan kepercayaan palsu pada model AI.
Mengapa Sistem Penjuji AI Sering Gagal
Masalah ini tidak sesederhana bug biasa dalam program komputer. Tim peneliti menemukan bahwa hakim LLM mudah terpengaruh oleh penalaran yg terdengar otoritatif. 2 Misalnya, ketika sistem RAG (Retrieval-Augmented Generation) tidak dapat menemukan data untuk menghitung metrik finansial, sistem tersebut akan menjelaskan bahwa informasi tidak tersedia - dan hakim LLM malah memberikan nilai penuh, menyimpulkan bahwa sistem berhasil mengidentifikasi ketiadaan data.
Permasalahan ini ternyata lebih kompleks. Evaluasi konten yg dihasilkan secara inheren bernuansa, dan hakim LLM rentan terhadap kegagalan halus namun konsekuensial. 3 CEO OpenAI Sam Altman bahkan memperingatkan bahwa media sosial seperti Twitter dan Reddit kini "terasa sangat palsu" karena banjir bot AI, dimana orang-orang bahkan mulai mengadopsi cara bicara AI atau "LLM-speak".
Tantangan Utama dlm Evaluasi AI
Para peneliti mengidentifikasi beberapa tantangan utama yg dihadapi sistem penilaian AI saat ini:
Ambiguitas Numerik dan Semantik
Apakah jawaban 3,9% cukup dekat dengan 3,8%? Hakim seringkali tidak memiliki konteks untuk memutuskan hal tersebut. 4 Begitu juga dengan kesetaraan semantik - apakah "APAC" merupakan pengganti yg dapat diterima untuk "Asia-Pacific: India, Japan, Malaysia, Philippines, Australia"?
Referensi yg Bermasalah
Terkadang jawaban "kebenaran mutlak" itu sendiri salah, meninggalkan hakim dalam paradoks. Hal ini menunjukkan bahwa kesepakatan sempurna antara hakim, baik manusia maupun mesin, tidak dapat dicapai tanpa pendekatan yg lebih ketat. 5
Solusi Framework Terpercaya
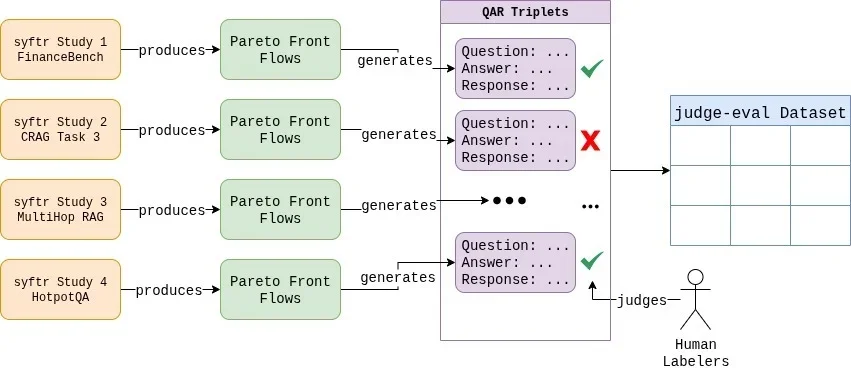
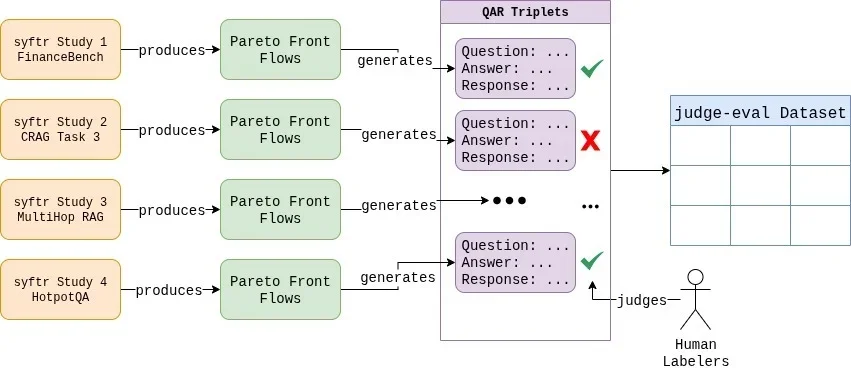
Untuk mengatasi tantangan ini, peneliti membutuhkan dua hal penting: dataset berlabel manusia berkualitas tinggi dan sistem untuk menguji konfigurasi hakim secara metodis. 6 Tim DataRobot menciptakan dataset mereka sendiri yg kini tersedia di HuggingFace, berisi ratusan triplet pertanyaan-jawaban-respons menggunakan berbagai sistem RAG.
Proses pelabelan manual dilakukan untuk semua 807 contoh, dimana setiap kasus tepi diperdebatkan dan aturan penilaian yg jelas dan konsisten ditetapkan. 7 Dataset berlabel tersebut mencerminkan distribusi 37,6% respons gagal dan 62,4% respons lulus. Fujitsu juga mengembangkan teknologi rekonstruksi AI generatif untuk model AI yg dioptimalkan dan hemat energi berdasarkan LLM Takane mereka.
Hasil Pengujian Mengejutkan
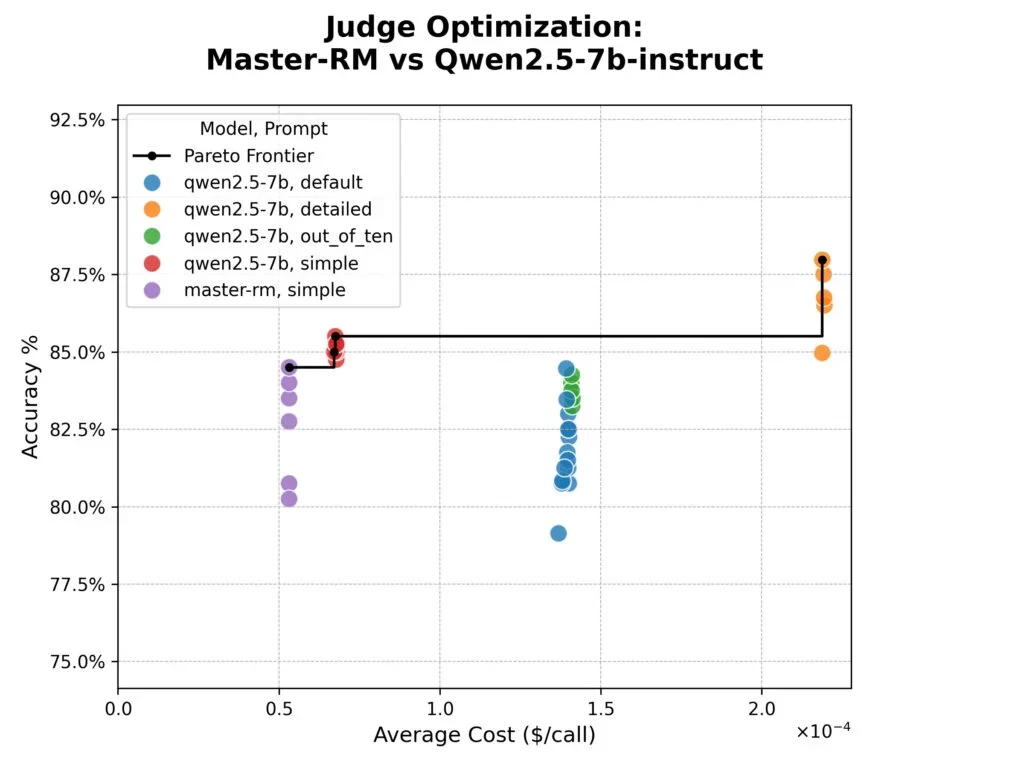
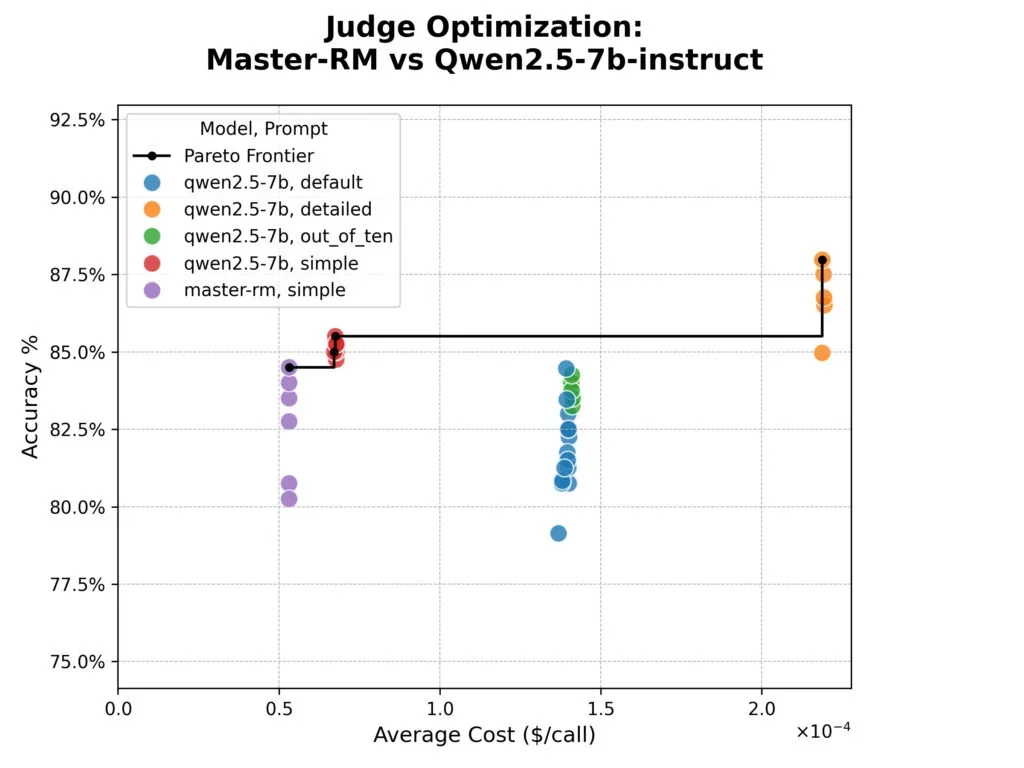
Eksperimen menunjukkan bahwa model Master-RM, yg secara khusus disetel untuk menghindari "reward hacking" dengan memprioritaskan konten daripada frasa penalaran, ternyata tidak lebih akurat daripada model dasarnya. 8 Meskipun pelatihan khusus model tersebut efektif dlm memerangi efek frasa penalaran spesifik, hal itu tidak meningkatkan keselarasan keseluruhan dgn penilaian manusia dalam dataset mereka.
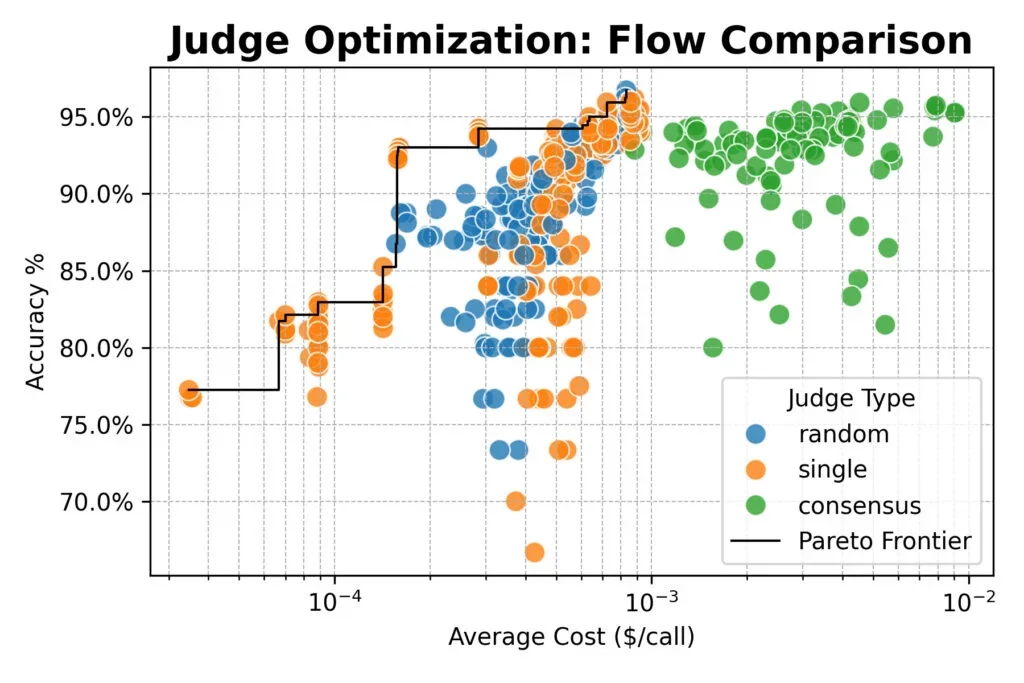
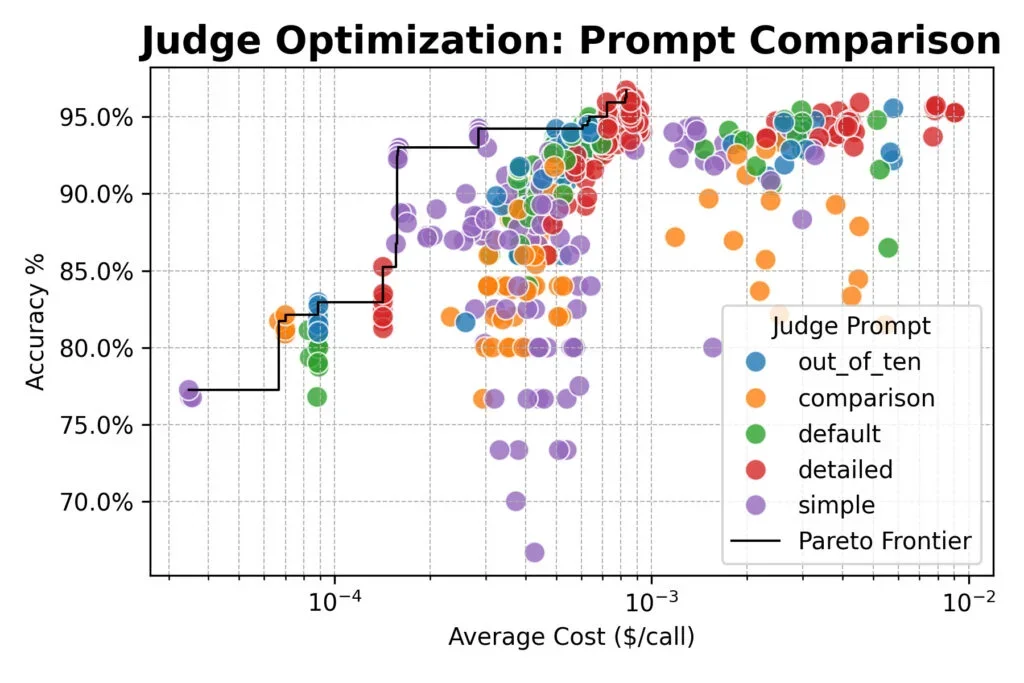
Penelitian juga mengungkap trade-off yg jelas: prompt "rinci" paling akurat namun hampir empat kali lebih mahal dalam token. 9 Hakim berbasis konsensus tidak menawarkan keunggulan akurasi dibandingkan hakim tunggal atau acak, dimana semua metode mencapai puncak sekitar 96% kesepakatan dgn label manusia.
Implikasi untuk Masa Depan AI
Temuan ini memiliki implikasi besar bagi industri AI. Selama ini, aturan praktis umum adalah "gunakan saja gpt-4o-mini" sebagai jalan pintas untuk tim yg mencari hakim yg andal dan siap pakai. 10 Namun eksperimen mengungkap batasannya - ini hanya satu titik dalam kurva trade-off yg jauh lebih luas.
Pendekatan sistematis memberikan menu opsi yg dioptimalkan alih-alih default tunggal. Untuk akurasi tertinggi tanpa memperhatikan biaya, alur konsensus dgn prompt rinci dan model seperti Qwen3-32B, DeepSeek-R1-Distill, dan Nemotron-Super-49B mencapai 96% keselarasan manusia. 11 Sementara untuk pengujian cepat yg ramah anggaran, model tunggal dgn prompt sederhana mencapai akurasi ~93% dengan biaya seperlima dari baseline gpt-4o-mini.
Kesimpulan
Perjalanan penelitian ini dimulai dgn penemuan yg meresahkan: alih-alih mengikuti rubrik, hakim LLM terpengaruh oleh penolakan panjang yg terdengar masuk akal. Dengan memperlakukan evaluasi sebagai masalah rekayasa yg ketat, para peneliti berhasil beralih dari keraguan ke kepercayaan. Mereka memperoleh pandangan yg jelas dan berbasis data tentang trade-off antara akurasi, biaya, dan kecepatan dalam sistem LLM-as-a-Judge. 12
Konfigurasi "terbaik" akan selalu bergantung pada kebutuhan spesifik, namun kita tidak lagi perlu menebak-nebak. Lebih banyak data berarti pilihan yg lebih baik dalam membangun evaluasi yg lebih dapat dipercaya.
Referensi
- Conway, A., Hackmann, S., Dey, D., Steadman, M., & Hausknecht, M. (2025, Agustus 26). Judging judges: Building trustworthy LLM evaluations. DataRobot Blog. https://www.datarobot.com/blog/llm-judges/
- Website. (2025, September 8). Sam Altman says 'real people have picked up quirks of LLM-speak' as AI Twitter and Reddit 'feel fake'. MSN Technology. https://www.msn.com/en-in/technology/artificial-intelligence/sam-altman-says-real-people-have-picked-up-quirks-of-llm-speak-as-ai-twitter-and-reddit-feel-fake/ar-AA1MagK6
- Website. (2025, September 9). OpenAI CEO Sam Altman Says Social Media Now Feels 'Fake' Due To AI Bots. Mashable India. https://in.mashable.com/tech/99555/openai-ceo-sam-altman-says-social-media-now-feels-fake-due-to-ai-bots
- Website. (2025, September 4). This new framework lets LLM agents learn from experience, no fine-tuning required. VentureBeat. https://venturebeat.com/ai/this-new-framework-lets-llm-agents-learn-from-experience-no-fine-tuning
- Website. (2025, September 8). All About AI Prompt Injection Attacks. Sify AI Analytics. https://www.sify.com/ai-analytics/all-about-ai-prompt-injection-attacks/
- Website. (2024, Mei 23). Retrieval Augmented Generation systems are reshaping the AI landscape. TechRadar Pro. https://www.techradar.com/pro/retrieval-augmented-generation-systems-are-reshaping-the-ai-landscape
- Website. (2025, Agustus 28). Comprehensive Guide to Deep Optimization of RAG Systems: High-Performance Implementation from Theory to Practice. Sohu Technology. https://www.sohu.com/a/929524202_122328931
- Website. (2025, September 7). Fujitsu develops generative AI reconstruction technology for optimized and energy-efficient AI models based on Takane LLM. Tirto. https://tirto.id/fujitsu-develops-generative-ai-reconstruction-technology-for-optimized-and-energy-efficient-ai-models-based-on-takane-ll-hhkH
- Website. (2025, September 8). PromptLock Only PoC, but AI-Powered Ransomware Is Real. Security Week. https://www.securityweek.com/promptlock-only-poc-but-ai-powered-ransomware-is-real/
- Website. (2025, September 8). Google's EmbeddingGemma: On-Device RAG Goes Mainstream. Stark Insider. https://www.starkinsider.com/2025/09/google-embeddinggemma-on-device-rag-search.html
- Website. (2025, Juli 31). 5 high-ROI uses of RAG models in banking and fintech. Finextra. https://www.finextra.com/blogposting/29032/5-high-roi-uses-of-rag-models-in-banking-and-fintech
- Website. (2025, Agustus 28). The AI Executive: Building Systems That Think Before You Do. Forbes Tech Council. https://www.forbes.com/councils/forbestechcouncil/2025/08/28/the-ai-executive-building-systems-that-think-before-you-do/